Research Projects
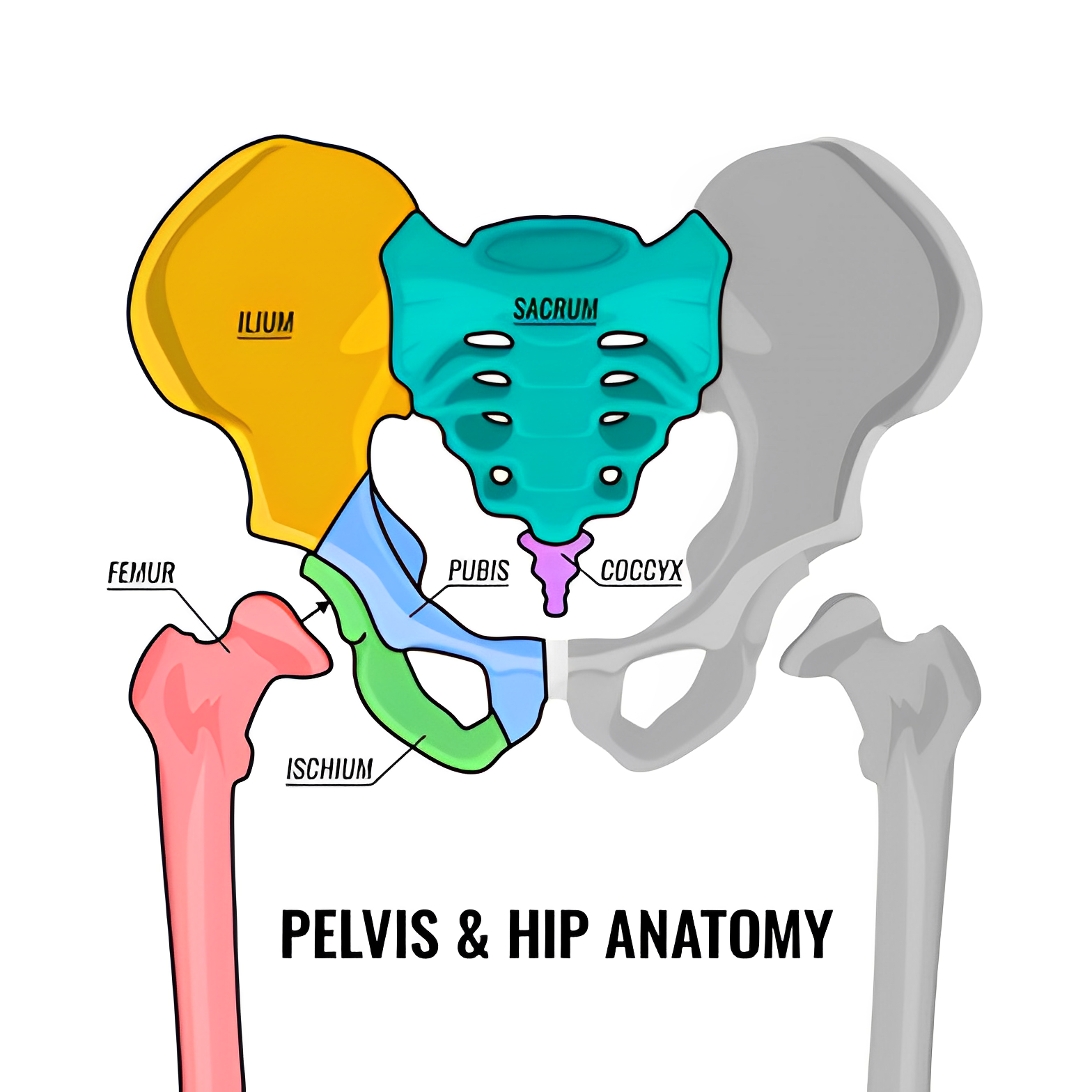
Pelvic Fracture and Bone Segmentation using Radiographic Images
The project aims to create an automatic bone segmentation model for the pelvic region using radiographic images. We utilized the Pelvic X-ray image dataset and manually annotated the images for each of the nine bones in the pelvic region using MITK Workbench. The goal of this project is to manually annotate the Sacrum (including the coccyx) (1), Ilium (2), Ischium (2), Pubis (2), and Femur (2) bones from opensource pelvic bone X-ray images, as well as to implement a machine learning model for multiclass semantic segmentation to detect and locate each of the nine pelvic bones and fractures in them. This project has potential applications in diagnosing pelvic fractures and other bone-related disorders.
- Duration: December 2022 - Present
- Role: Research Assistant
- Skills: Medical Imaging, Image Processing, Image Segmentation, Data Collection, Data Annotation
- Supervisor: Dr. Saadia Binte Alam

Video Censorship and Rating
The aim of the project is to create an automated film censorship and rating (AFCR) system that recognizes, classifies, and rates sensitive audio-visual components of films using deep learning techniques. According to the project, many videos contain violence, nudity, adult content, substance misuse, or profanity, which are unacceptable for uncongenial viewers and can harm the younger generation, prompting calls for their restriction. The research examines an efficient, automated, and acceptable film content grading system based on different DL approaches. The AFCR system can assist in ensuring age-appropriate video watching and can be used for a variety of purposes ranging from content classification to real-time surveillance.
- Duration: January 2021 - Present
- Role: Project Lead
- Skills: Activity Recognition, Video Classification, Image Processing, Model Optimisation
- Supervisor: Dr. Hussain Md Abu Nyeem
Sign Language Translation
This project focuses on sign language translation (SLT) to overcome communication barriers for individuals with speech and hearing disabilities. We present a novel approach using deep learning techniques to develop a 2D convolutional neural network (CNN) model. Unlike existing models, we train our model on binary Sign Language (SL) image datasets with a preprocessing step of binarization to improve classification accuracy. Our model demonstrates impressive results, achieving high accuracy when tested on the NVIDIA Tesla K80 GPU environment (Google Colab). This research highlights the potential of our automatic SLT system, offering a promising solution for real-time translation of hand-gestured SL into natural language (NL). By leveraging computer vision and deep learning, our project contributes to improving accessibility and fostering effective communication for the hearing impaired.
- Duration: April 2021 - November 2021
- Role: Project Lead
- Skills: Object Classification, Image Processing
- Supervisor: Dr. Hussain Md Abu Nyeem
Traffic Surveillance
This project introduces a sophisticated traffic surveillance system that employs a YOLOv4 object detection model to detect license plates of vehicles in Bangladesh. The model is trained and fine-tuned using convolutional neural networks (CNN) to achieve accurate license plate detection. Additionally, we leverage Tesseract OCR to recognize characters on the license plates. The system is further enhanced with a user-friendly Graphical User Interface (GUI) built using Tkinter. By combining these technologies, we enable real-time license plate detection and character recognition from video footage. Our system contributes to improved traffic monitoring, law enforcement, and security measures. The project showcases promising results, including a high mean average precision (mAP) and efficient performance on a single TESLA T4 GPU.
- Duration: June 2020 - December 2020
- Role: Project Team Member
- Skills: Object Detetction, Object Classification, OCR, Image Processing, Nodel Optimisation, Data Collection, Data Annotation
- Team Lead: Md. Saif Hossain Onim